I have been using embedded python for more than 2 years now on a daily basis.
May be it's time to share some feedback about this journey.
Why write this feedback? Because, I guess, I'm like most of the people here, an ObjectScript developer, and I think that the community would benefit from this feedback and could better understand the pros & cons of chosing embedded python for developing stuff in IRIS. And also avoid some pitfalls.

Introduction
I'm a developer since 2010, and I have been working with ObjectScript since 2013.
So roughly 10 years of experience with ObjectScript.
Since 2021 and the release of Embedded Python in IRIS, I put my self a challenge :
- Learn Python
- Do as much as possible everything in Python
When I started this journey, I had no idea of what Python was. So I started with the basics, and I'm still learning every day.
Starting with Python
The good thing with Python is that it's easy to learn. It's even easier when you already know ObjectScript.
Why ? They have a lot in common.
| ObjectScript | Python |
|---|
| Untyped | Untyped |
| Scripting language | Scripting language |
| Object Oriented | Object Oriented |
| Interpreted | Interpreted |
| Easy C integration | Easy C integration |
So, if you know ObjectScript, you already know a lot about Python.
But, there are some differences, and some of them are not easy to understand.
Python is not ObjectScript
To keep it simple, I will focus on the main differences between ObjectScript and Python.
For me there are mainly 3 differences :
Pep8
What the hell is Pep8 ?
It's a set of rules to write Python code.
pep8.org
Few of them are :
- naming convention
- variable names
- class names
- indentation
- line length
- etc.
Why is it important ?
Because it's the way to write Python code. And if you don't follow these rules, you will have a hard time to read other people's code, and they will have a hard time to read your code.
As ObjectScript developers, we also have some rules to follow, but they are not as strict as Pep8.
I learned Pep8 the hard way.
For the story, I'm a sales engineer at InterSystems, and I'm doing a lot of demos. And one day, I was doing a demo of Embedded Python to a customer, this customer was a Python developer, and the conversation turned short when he saw my code. He told me that my code was not Pythonic at all (he was right) I was coding in python like I was coding in ObjectScript. And because of that, he told me that he was not interested in Embedded Python anymore. I was shocked, and I decided to learn Python the right way.
So, if you want to learn Python, learn Pep8 first.
Modules
Modules are something that we don't have in ObjectScript.
Usually, in object oriented languages, you have classes, and packages. In Python, you have classes, packages, and modules.
What is a module ?
It's a file with a .py extension. And it's the way to organize your code.
You didn't understand ? Me neither at the beginning. So let's take an example.
Usually, when you want to create a class in ObjectScript, you create a .cls file, and you put your class in it. And if you want to create another class, you create another .cls file. And if you want to create a package, you create a folder, and you put your .cls files in it.
In Python, it's the same, but Python bring the ability to have multiple classes in a single file. And this file is called a module.
FYI, It's Pythonic to have multiple classes in a single file.
So plan head how you will organize your code, and how you will name your modules to not end up like me with a lot of modules with the same name as your classes.
A bad example :
MyClass.py
class MyClass:
def __init__(self):
pass
def my_method(self):
pass
To instantiate this class, you will do :
import MyClass.MyClass # weird right ?
my_class = MyClass()
Weird right ?
Dunders
Dunders are special methods in Python. They are called dunder because they start and end with double underscores.
They are kind of our % methods in ObjectScript.
They are used for :
- constructor
- operator overloading
- object representation
- etc.
Example :
class MyClass:
def __init__(self):
pass
def __repr__(self):
return "MyClass"
def __add__(self, other):
return self + other
Here we have 3 dunder methods :
__init__ : constructor__repr__ : object representation__add__ : operator overloading
Dunders methods are everywhere in Python. It's a major part of the language, but don't worry, you will learn them quickly.
Conclusion
Python is not ObjectScript, and you will have to learn it. But it's not that hard, and you will learn it quickly.
Just keep in mind that you will have to learn Pep8, and how to organize your code with modules and dunder methods.
Good sites to learn Python :
Embedded Python
Now that you know a little bit more about Python, let's talk about Embedded Python.
What is Embedded Python ?
Embedded Python is a way to execute Python code in IRIS. It's a new feature of IRIS 2021.2+.
This means that your python code will be executed in the same process as IRIS.
For the more, every ObjectScript class is a Python class, same for methods and attributes and vice versa. 🥳
This is neat !
How to use Embedded Python ?
There are 3 main ways to use Embedded Python :
- Using the language tag in ObjectScript
- Method Foo() As %String [ Language = python ]
- Using the ##class(%SYS.Python).Import() function
- Using the python interpreter
- python3 -c "import iris; print(iris.system.Version.GetVersion())"
But if you want to be serious about Embedded Python, you will have to avoid using the language tag.

Why ?
- Because it's not Pythonic
- Because it's not ObjectScript either
- Because you don't have a debugger
- Because you don't have a linter
- Because you don't have a formatter
- Because you don't have a test framework
- Because you don't have a package manager
- Because you are mixing 2 languages in the same file
- Because when you process crashes, you don't have a stack trace
- Because you can't use virtual environments or conda environments
- ...
Don't get me wrong, it works, it can be useful, if you want to test something quickly, but IMO it's not a good practice.
So, what did I learn from this 2 years of Embedded Python, and how to use it the right way ?
How I use Embedded Python
For me, you have two options :
- Use Python libraries as they were ObjectScript classes
- with ##class(%SYS.Python).Import() function
- Use a python first approach
Use Python libraries and code as they were ObjectScript classes
You still want to use Python in your ObjectScript code, but you don't want to use the language tag. So what can you do ?
"Simply" use Python libraries and code as they were ObjectScript classes.
Let's take an example :
You want to use the requests library ( it's a library to make HTTP requests ) in your ObjectScript code.
With the language tag
ClassMethod Get() As %Status [ Language = python ]
{
import requests
url = "https://httpbin.org/get"
# make a get request
response = requests.get(url)
# get the json data from the response
data = response.json()
# iterate over the data and print key-value pairs
for key, value in data.items():
print(key, ":", value)
}
Why I think it's not a good idea ?
Because you are mixing 2 languages in the same file, and you don't have a debugger, a linter, a formatter, etc.
If this code crashes, you will have a hard time to debug it.
You don't have a stack trace, and you don't know where the error comes from.
And you don't have auto-completion.
Without the language tag
ClassMethod Get() As %Status
{
set status = $$$OK
set url = "https://httpbin.org/get"
// Import Python module "requests" as an ObjectScript class
set request = ##class(%SYS.Python).Import("requests")
// Call the get method of the request class
set response = request.get(url)
// Call the json method of the response class
set data = response.json()
// Here data is a Python dictionary
// To iterate over a Python dictionary, you have to use the dunder method and items()
// Import built-in Python module
set builtins = ##class(%SYS.Python).Import("builtins")
// Here we are using len from the builtins module to get the length of the dictionary
For i = 0:1:builtins.len(data)-1 {
// Now we convert the items of the dictionary to a list, and we get the key and the value using the dunder method __getitem__
Write builtins.list(data.items())."__getitem__"(i)."__getitem__"(0),": ",builtins.list(data.items())."__getitem__"(i)."__getitem__"(1),!
}
quit status
}
Why I think it's a good idea ?
Because you are using Python as it was ObjectScript. You are importing the requests library as an ObjectScript class, and you are using it as an ObjectScript class.
All the logic is in ObjectScript, and you are using Python as a library.
Even for maintenance, it's easier to read and understand, any ObjectScript developer can understand this code.
The drawback is that you have to know how to use duners methods, and how to use Python as it was ObjectScript.
Conclusion
Belive me, this way you will end up with a more robust code, and you will be able to debug it easily.
At first, it's seems hard, but you will find the benefits of learning Python faster than you think.
Use a python first approach
This is the way I prefer to use Embedded Python.
I have built a lot of tools using this approach, and I'm very happy with it.
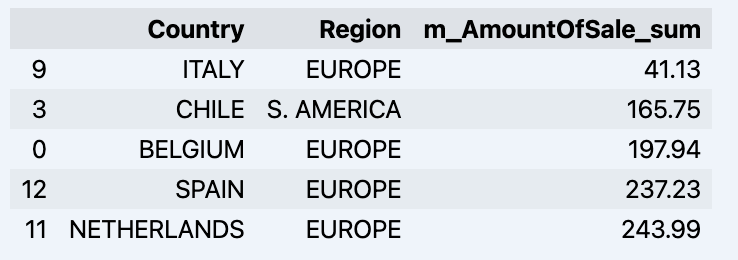
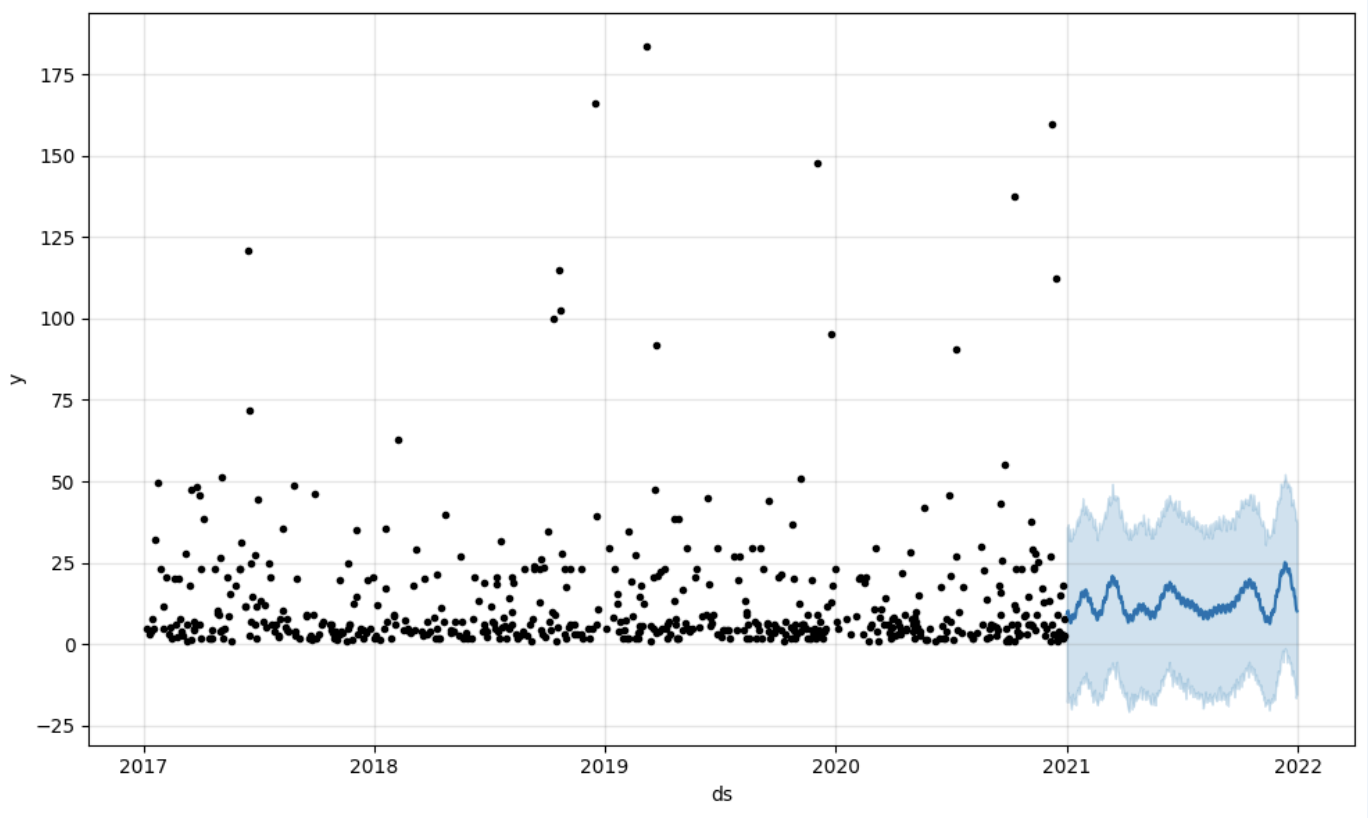
Few examples :
So, what is a python first approach ?
There is only one rule : Python code must be in .py files, ObjectScript code must be in .cls files
How to achieve this ?
The whole idea is to create ObjectScript wrappers classes to call Python code.
Let's take the example of iris-fhir-python-strategy :
Example : iris-fhir-python-strategy
First of all, we have to understand how IRIS FHIR Server works.
Every IRIS FHIR Server implements a Strategy.
A Strategy is a set of two classes :
| Superclass | Subclass Parameters |
|---|
| HS.FHIRServer.API.InteractionsStrategy | StrategyKey — Specifies a unique identifier for the InteractionsStrategy.
InteractionsClass — Specifies the name of your Interactions subclass. |
| HS.FHIRServer.API.RepoManager | StrategyClass — Specifies the name of your InteractionsStrategy subclass.
StrategyKey — Specifies a unique identifier for the InteractionsStrategy. Must match the StrategyKey parameter in the InteractionsStrategy subclass. |
Both classes are Abstract classes.
HS.FHIRServer.API.InteractionsStrategy is an Abstract class that must be implemented to customize the behavior of the FHIR Server.HS.FHIRServer.API.RepoManager is an Abstract class that must be implemented to customize the storage of the FHIR Server.
Remarks
For our example, we will only focus on the HS.FHIRServer.API.InteractionsStrategy class even if the HS.FHIRServer.API.RepoManager class is also implemented and mandatory to customize the FHIR Server.
The HS.FHIRServer.API.RepoManager class is implemented by HS.FHIRServer.Storage.Json.RepoManager class, which is the default implementation of the FHIR Server.
Where to find the code
All source code can be found in this repository : iris-fhir-python-strategy
The src folder contains the following folders :
python : contains the python codecls : contains the ObjectScript code that is used to call the python code
How to implement a Strategy
In this proof of concept, we will only be interested in how to implement a Strategy in Python, not how to implement a RepoManager.
To implement a Strategy you need to create at least two classes :
- A class that inherits from
HS.FHIRServer.API.InteractionsStrategy class - A class that inherits from
HS.FHIRServer.API.Interactions class
Implementation of InteractionsStrategy
HS.FHIRServer.API.InteractionsStrategy class aim to customize the behavior of the FHIR Server by overriding the following methods :
GetMetadataResource : called to get the metadata of the FHIR Server
- this is the only method we will override in this proof of concept
HS.FHIRServer.API.InteractionsStrategy has also two parameters :
StrategyKey : a unique identifier for the InteractionsStrategyInteractionsClass : the name of your Interactions subclass
Implementation of Interactions
HS.FHIRServer.API.Interactions class aim to customize the behavior of the FHIR Server by overriding the following methods :
OnBeforeRequest : called before the request is sent to the serverOnAfterRequest : called after the request is sent to the serverPostProcessRead : called after the read operation is donePostProcessSearch : called after the search operation is doneRead : called to read a resourceAdd : called to add a resourceUpdate : called to update a resourceDelete : called to delete a resource- and many more...
We implement HS.FHIRServer.API.Interactions class in the src/cls/FHIR/Python/Interactions.cls class.
Class FHIR.Python.Interactions Extends (HS.FHIRServer.Storage.Json.Interactions, FHIR.Python.Helper)
{
Parameter OAuth2TokenHandlerClass As%String = "FHIR.Python.OAuth2Token"
Method %OnNew(pStrategy As HS.FHIRServer.Storage.Json.InteractionsStrategy) As%Status
{
set..PythonPath = $system.Util.GetEnviron("INTERACTION_PATH")
set..PythonClassname = $system.Util.GetEnviron("INTERACTION_CLASS")
set..PythonModule = $system.Util.GetEnviron("INTERACTION_MODULE")
<span class="hljs-keyword">if</span> (<span class="hljs-built_in">..PythonPath</span> = <span class="hljs-string">""</span>) || (<span class="hljs-built_in">..PythonClassname</span> = <span class="hljs-string">""</span>) || (<span class="hljs-built_in">..PythonModule</span> = <span class="hljs-string">""</span>) {
<span class="hljs-comment">//quit ##super(pStrategy)</span>
<span class="hljs-keyword">set</span> <span class="hljs-built_in">..PythonPath</span> = <span class="hljs-string">"/irisdev/app/src/python/"</span>
<span class="hljs-keyword">set</span> <span class="hljs-built_in">..PythonClassname</span> = <span class="hljs-string">"CustomInteraction"</span>
<span class="hljs-keyword">set</span> <span class="hljs-built_in">..PythonModule</span> = <span class="hljs-string">"custom"</span>
}
<span class="hljs-comment">// Then set the python class</span>
<span class="hljs-keyword">do</span> <span class="hljs-built_in">..SetPythonPath</span>(<span class="hljs-built_in">..PythonPath</span>)
<span class="hljs-keyword">set</span> <span class="hljs-built_in">..PythonClass</span> = <span class="hljs-keyword">##class</span>(FHIR.Python.Interactions).GetPythonInstance(<span class="hljs-built_in">..PythonModule</span>, <span class="hljs-built_in">..PythonClassname</span>)
<span class="hljs-keyword">quit</span> <span class="hljs-keyword">##super</span>(pStrategy)
}
Method OnBeforeRequest(
pFHIRService As HS.FHIRServer.API.Service,
pFHIRRequest As HS.FHIRServer.API.Data.Request,
pTimeout As%Integer)
{
if$ISOBJECT(..PythonClass) {
set body = ##class(%SYS.Python).None()
if pFHIRRequest.Json '= "" {
set jsonLib = ##class(%SYS.Python).Import("json")
set body = jsonLib.loads(pFHIRRequest.Json.%ToJSON())
}
do..PythonClass."on_before_request"(pFHIRService, pFHIRRequest, body, pTimeout)
}
}
Method OnAfterRequest(
pFHIRService As HS.FHIRServer.API.Service,
pFHIRRequest As HS.FHIRServer.API.Data.Request,
pFHIRResponse As HS.FHIRServer.API.Data.Response)
{
if$ISOBJECT(..PythonClass) {
set body = ##class(%SYS.Python).None()
if pFHIRResponse.Json '= "" {
set jsonLib = ##class(%SYS.Python).Import("json")
set body = jsonLib.loads(pFHIRResponse.Json.%ToJSON())
}
do..PythonClass."on_after_request"(pFHIRService, pFHIRRequest, pFHIRResponse, body)
}
}
Method PostProcessRead(pResourceObject As%DynamicObject) As%Boolean
{
if$ISOBJECT(..PythonClass) {
if pResourceObject '= "" {
set jsonLib = ##class(%SYS.Python).Import("json")
set body = jsonLib.loads(pResourceObject.%ToJSON())
}
return..PythonClass."post_process_read"(body)
}
quit1
}
Method PostProcessSearch(
pRS As HS.FHIRServer.Util.SearchResult,
pResourceType As%String) As%Status
{
if$ISOBJECT(..PythonClass) {
return..PythonClass."post_process_search"(pRS, pResourceType)
}
quit$$$OK
}
Method Read(
pResourceType As%String,
pResourceId As%String,
pVersionId As%String = "") As%DynamicObject
{
return##super(pResourceType, pResourceId, pVersionId)
}
Method Add(
pResourceObj As%DynamicObject,
pResourceIdToAssign As%String = "",
pHttpMethod = "POST") As%String
{
return##super(pResourceObj, pResourceIdToAssign, pHttpMethod)
}
Method Delete(
pResourceType As%String,
pResourceId As%String) As%String
{
return##super(pResourceType, pResourceId)
}
Method Update(pResourceObj As%DynamicObject) As%String
{
return##super(pResourceObj)
}
}
The FHIR.Python.Interactions class inherits from HS.FHIRServer.Storage.Json.Interactions class and FHIR.Python.Helper class.
The HS.FHIRServer.Storage.Json.Interactions class is the default implementation of the FHIR Server.
The FHIR.Python.Helper class aim to help to call Python code from ObjectScript.
The FHIR.Python.Interactions class overrides the following methods :
%OnNew : called when the object is created
- we use this method to set the python path, python class name and python module name from environment variables
- if the environment variables are not set, we use default values
- we also set the python class
- we call the
%OnNew method of the parent class
Method %OnNew(pStrategy As HS.FHIRServer.Storage.Json.InteractionsStrategy) As %Status
{
// First set the python path from an env var
set ..PythonPath = $system.Util.GetEnviron("INTERACTION_PATH")
// Then set the python class name from the env var
set ..PythonClassname = $system.Util.GetEnviron("INTERACTION_CLASS")
// Then set the python module name from the env var
set ..PythonModule = $system.Util.GetEnviron("INTERACTION_MODULE")
if (..PythonPath = "") || (..PythonClassname = "") || (..PythonModule = "") {
// use default values
set ..PythonPath = "/irisdev/app/src/python/"
set ..PythonClassname = "CustomInteraction"
set ..PythonModule = "custom"
}
// Then set the python class
do ..SetPythonPath(..PythonPath)
set ..PythonClass = ..GetPythonInstance(..PythonModule, ..PythonClassname)
quit ##super(pStrategy)
}
OnBeforeRequest : called before the request is sent to the server
- we call the
on_before_request method of the python class - we pass the
HS.FHIRServer.API.Service object, the HS.FHIRServer.API.Data.Request object, the body of the request and the timeout
Method OnBeforeRequest(
pFHIRService As HS.FHIRServer.API.Service,
pFHIRRequest As HS.FHIRServer.API.Data.Request,
pTimeout As %Integer)
{
// OnBeforeRequest is called before each request is processed.
if $ISOBJECT(..PythonClass) {
set body = ##class(%SYS.Python).None()
if pFHIRRequest.Json '= "" {
set jsonLib = ##class(%SYS.Python).Import("json")
set body = jsonLib.loads(pFHIRRequest.Json.%ToJSON())
}
do ..PythonClass."on_before_request"(pFHIRService, pFHIRRequest, body, pTimeout)
}
}
OnAfterRequest : called after the request is sent to the server
- we call the
on_after_request method of the python class - we pass the
HS.FHIRServer.API.Service object, the HS.FHIRServer.API.Data.Request object, the HS.FHIRServer.API.Data.Response object and the body of the response
Method OnAfterRequest(
pFHIRService As HS.FHIRServer.API.Service,
pFHIRRequest As HS.FHIRServer.API.Data.Request,
pFHIRResponse As HS.FHIRServer.API.Data.Response)
{
// OnAfterRequest is called after each request is processed.
if $ISOBJECT(..PythonClass) {
set body = ##class(%SYS.Python).None()
if pFHIRResponse.Json '= "" {
set jsonLib = ##class(%SYS.Python).Import("json")
set body = jsonLib.loads(pFHIRResponse.Json.%ToJSON())
}
do ..PythonClass."on_after_request"(pFHIRService, pFHIRRequest, pFHIRResponse, body)
}
}
Interactions in Python
FHIR.Python.Interactions class calls the on_before_request, on_after_request, ... methods of the python class.
Here is the abstract python class :
import abc
import iris
class Interaction(object):
__metaclass__ = abc.ABCMeta
@abc.abstractmethod
def on_before_request(self,
fhir_service:'iris.HS.FHIRServer.API.Service',
fhir_request:'iris.HS.FHIRServer.API.Data.Request',
body:dict,
timeout:int):
"""
on_before_request is called before the request is sent to the server.
param fhir_service: the fhir service object iris.HS.FHIRServer.API.Service
param fhir_request: the fhir request object iris.FHIRServer.API.Data.Request
param timeout: the timeout in seconds
return: None
"""
@abc.abstractmethod
def on_after_request(self,
fhir_service:'iris.HS.FHIRServer.API.Service',
fhir_request:'iris.HS.FHIRServer.API.Data.Request',
fhir_response:'iris.HS.FHIRServer.API.Data.Response',
body:dict):
"""
on_after_request is called after the request is sent to the server.
param fhir_service: the fhir service object iris.HS.FHIRServer.API.Service
param fhir_request: the fhir request object iris.FHIRServer.API.Data.Request
param fhir_response: the fhir response object iris.FHIRServer.API.Data.Response
return: None
"""
@abc.abstractmethod
def post_process_read(self,
fhir_object:dict) -> bool:
"""
post_process_read is called after the read operation is done.
param fhir_object: the fhir object
return: True the resource should be returned to the client, False otherwise
"""
@abc.abstractmethod
def post_process_search(self,
rs:'iris.HS.FHIRServer.Util.SearchResult',
resource_type:str):
"""
post_process_search is called after the search operation is done.
param rs: the search result iris.HS.FHIRServer.Util.SearchResult
param resource_type: the resource type
return: None
"""
Implementation of the abstract python class
from FhirInteraction import Interaction
class CustomInteraction(Interaction):
def on_before_request(self, fhir_service, fhir_request, body, timeout):
#Extract the user and roles for this request
#so consent can be evaluated.
self.requesting_user = fhir_request.Username
self.requesting_roles = fhir_request.Roles
def on_after_request(self, fhir_service, fhir_request, fhir_response, body):
#Clear the user and roles between requests.
self.requesting_user = ""
self.requesting_roles = ""
def post_process_read(self, fhir_object):
#Evaluate consent based on the resource and user/roles.
#Returning 0 indicates this resource shouldn't be displayed - a 404 Not Found
#will be returned to the user.
return self.consent(fhir_object['resourceType'],
self.requesting_user,
self.requesting_roles)
def post_process_search(self, rs, resource_type):
#Iterate through each resource in the search set and evaluate
#consent based on the resource and user/roles.
#Each row marked as deleted and saved will be excluded from the Bundle.
rs._SetIterator(0)
while rs._Next():
if not self.consent(rs.ResourceType,
self.requesting_user,
self.requesting_roles):
#Mark the row as deleted and save it.
rs.MarkAsDeleted()
rs._SaveRow()
def consent(self, resource_type, user, roles):
#Example consent logic - only allow users with the role '%All' to see
#Observation resources.
if resource_type == 'Observation':
if '%All' in roles:
return True
else:
return False
else:
return True
Too long, do a summary
The FHIR.Python.Interactions class is a wrapper to call the python class.
IRIS abstracts classes are implemented to wrap python abstract classes 🥳.
That help us to keep python code and ObjectScript code separated and for so benefit from the best of both worlds.





.jpg)



