In the world of APIs, REST is very extended. But what happens when you need more flexibility in your data-fetching strategies? For instance letting the client to choose what fields is going to receive. Enter GraphQL, a query language for your APIs that provides a flexible alternative to REST.
In this post, we will:
- Compare REST and GraphQL.
- Dive into the basics of GraphQL: Queries, Mutations, and HTTP.
- Build a simple GraphQL server implementation using Graphene, SQLAlchemy, and Flask over data in InterSystems IRIS.
- Explore how to deploy your GraphQL server as a WSGI application in IRIS.
Grab a coffee ☕ and let's go:
REST vs. GraphQL: The Key Differences
Let’s start by comparing REST and GraphQL side by side:
| Feature | REST | GraphQL |
|---|
| Data Fetching | Multiple endpoints for resources | Single endpoint for all queries |
| Flexibility | Predefined responses | Query exactly what you need |
| Overfetching | Getting too much data for client needs | Solves overfetching |
| Underfetching | Needing multiple calls to get enough data | Solves underfetching |
| Versioning | Requires version management (e.g. /api/v1/users) | "Versionless" as clients can choose the fields they need. Also, schemas are typed and can evolve |
The good news is that both use HTTP so they are pretty easy to consume from client applications.
Getting Started with GraphQL
GraphQL is built around three main concepts:
Queries: Retrieve data from your API.
query {
allEmployees(hiredAfter: "2020-01-01") {
name
hiredon
}
}
query keyword indicates a read operation (although it can be omitted)allEmployees is the field that represents a list of employees. In the server, a resolver function in the GraphQL schema will fetch the data. It takes (hiredAfter: "2020-01-01") as an argument that is used to filter data.name and hiredon are subfields that we are selecting to be returned
Mutations: Modify data
mutation {
createEmployee(name: "John", lastname: "Doe", position: "Developer", hiredon: "2021-11-30", departmentId: "1") {
employee {
name
lastname
department {
name
}
}
}
}
mutation indicates an operation that will modify datacreateEmployee is the mutation field that handles the creation of a new employee (a resolver function in the GraphQL schema will handle that). It takes different arguments to define the new employee.- After creating the new employee, the mutation will return an object that includes details about the newly created employee (this is defined by
employee and structure containing name, lastname and department with some nested fields).
- HTTP: Works over POST/GET requests to a single endpoint, typically
/graphql.
For example, the previous query could be sent as:
curl -X POST \
-H "Content-Type: application/json" \
-d '{"query": "query { allEmployees(hiredAfter: \"2020-01-01\") { name hiredon } }"}' \
http://localhost:5000/graphql
And the response data could be:
{"data":{"allEmployees":[{"name":"Alice","hiredon":"2020-06-15"},{"name":"Clara","hiredon":"2021-09-01"},{"name":"Eve","hiredon":"2022-01-05"},{"name":"Frank","hiredon":"2020-11-15"},{"name":"John","hiredon":"2021-11-30"},{"name":"Phileas","hiredon":"2023-11-27"}]}}
Building a GraphQL Server with InterSystems IRIS
We will use this tools ⚒️:
- Graphene: To define GraphQL schemas and queries.
- SQLAlchemy: For database interaction.
- Flask: As the web framework.
- InterSystems IRIS: Our data platform where we will storage data.
📝 You will find detailed instructions on setting up InterSystems IRIS Community and a Python virtual environment in iris-graphql-demo.
Now let's focus on the main steps you need to do.
Step 1: Define the Data Model
We will use a simple model with Employee and Department tables that will be created and populated in InterSystems IRIS.
Create a models.py file with:
from sqlalchemy import *
from sqlalchemy.orm import relationship, declarative_base, Session, scoped_session, sessionmaker, relationship, backref
engine = create_engine('iris://superuser:SYS@localhost:1972/USER')
db_session = scoped_session(sessionmaker(bind=engine))
Base = declarative_base()
Base.query = db_session.query_property()
class Department(Base):
__tablename__ = 'departments'
__table_args__ = {'schema': 'dc_graphql'}
id = Column(Integer, primary_key=True)
name = Column(String, nullable=False)
description = Column(String)
employees = relationship('Employee', back_populates='department')
class Employee(Base):
__tablename__ = 'employees'
__table_args__ = {'schema': 'dc_graphql'}
id = Column(Integer, primary_key=True)
name = Column(String, nullable=False)
lastname = Column(String, nullable=False)
hiredon = Column(Date)
position = Column(String)
department_id = Column(Integer, ForeignKey('dc_graphql.departments.id'))
department = relationship('Department', back_populates='employees')
Step 2: Create the GraphQL Schema
Let's define the GraphQL Schema using Graphene using the models we have just defined.
In the related OpenExchange application you will find a version that also implements a mutation.
Create a schema.py file with this content:
import graphene
from graphene_sqlalchemy import SQLAlchemyObjectType, SQLAlchemyConnectionField
from models import db_session, Employee, Department
class DepartmentType(SQLAlchemyObjectType):
class Meta:
model = Department
interfaces = ()
class EmployeeType(SQLAlchemyObjectType):
class Meta:
model = Employee
interfaces = ()
class Query(graphene.ObjectType):
all_departments = graphene.List(DepartmentType)
all_employees = graphene.List(
EmployeeType,
hired_after=graphene.Date(),
position=graphene.String()
)
def resolve_all_departments(self, info):
return db_session.query(Department).all()
def resolve_all_employees(self, info, hired_after=None, position=None):
query = db_session.query(Employee)
if hired_after:
query = query.filter(Employee.hiredon > hired_after)
if position:
query = query.filter(Employee.position == position)
return query.all()
schema = graphene.Schema(query=Query)
Step 3: Set Up Flask
And we will need also a Flask application that sets up the /graphql endpoint.
Create an app.py file like this:
from flask import Flask, request, jsonify
from flask_graphql import GraphQLView
from schema import schema
app = Flask(__name__)
@app.teardown_appcontext
def shutdown_session(exception=None):
db_session.remove()
app.add_url_rule(
'/graphql',
view_func=GraphQLView.as_view(
'graphql',
schema=schema,
graphiql=True,
)
)
if __name__ == '__main__':
app.run(debug=True)
Step 4: Create some data
We could create the tables and insert some data using SQL or ObjectScript.
But, if you are exploring the capabilities of Python + InterSystems IRIS I recommend you to use Python 🐍 directly.
Open an interactive Python session:
python
And then:
from models import db_session, engine, Base, Department, Employee
# this will create the tables for you in InterSytems IRIS
Base.metadata.create_all(bind=engine)
# add departments
engineering = Department(name='Engineering', description='Handles product development and technology')
hr = Department(name='Human Resources', description='Manages employee well-being and recruitment')
sales = Department(name='Sales', description='Responsible for sales and customer relationships')
db_session.add_all([engineering, hr, sales])
# add employees
employees = [
Employee(name='Alice', lastname='Smith', hiredon=date(2020, 6, 15), position='Software Engineer', department=engineering),
Employee(name='Bob', lastname='Brown', hiredon=date(2019, 3, 10), position='QA Engineer', department=engineering),
Employee(name='Clara', lastname='Johnson', hiredon=date(2021, 9, 1), position='Recruiter', department=hr),
Employee(name='David', lastname='Davis', hiredon=date(2018, 7, 22), position='HR Manager', department=hr),
Employee(name='Eve', lastname='Wilson', hiredon=date(2022, 1, 5), position='Sales Executive', department=sales),
Employee(name='Frank', lastname='Taylor', hiredon=date(2020, 11, 15), position='Account Manager', department=sales)
]
db_session.add_all(employees)
db_session.commit()
Step 5: Test your server
First, you will need to run your server:
python app.py
Then you can start testing your server using an included GraphiQL UI in http://localhost:5000/graphql.
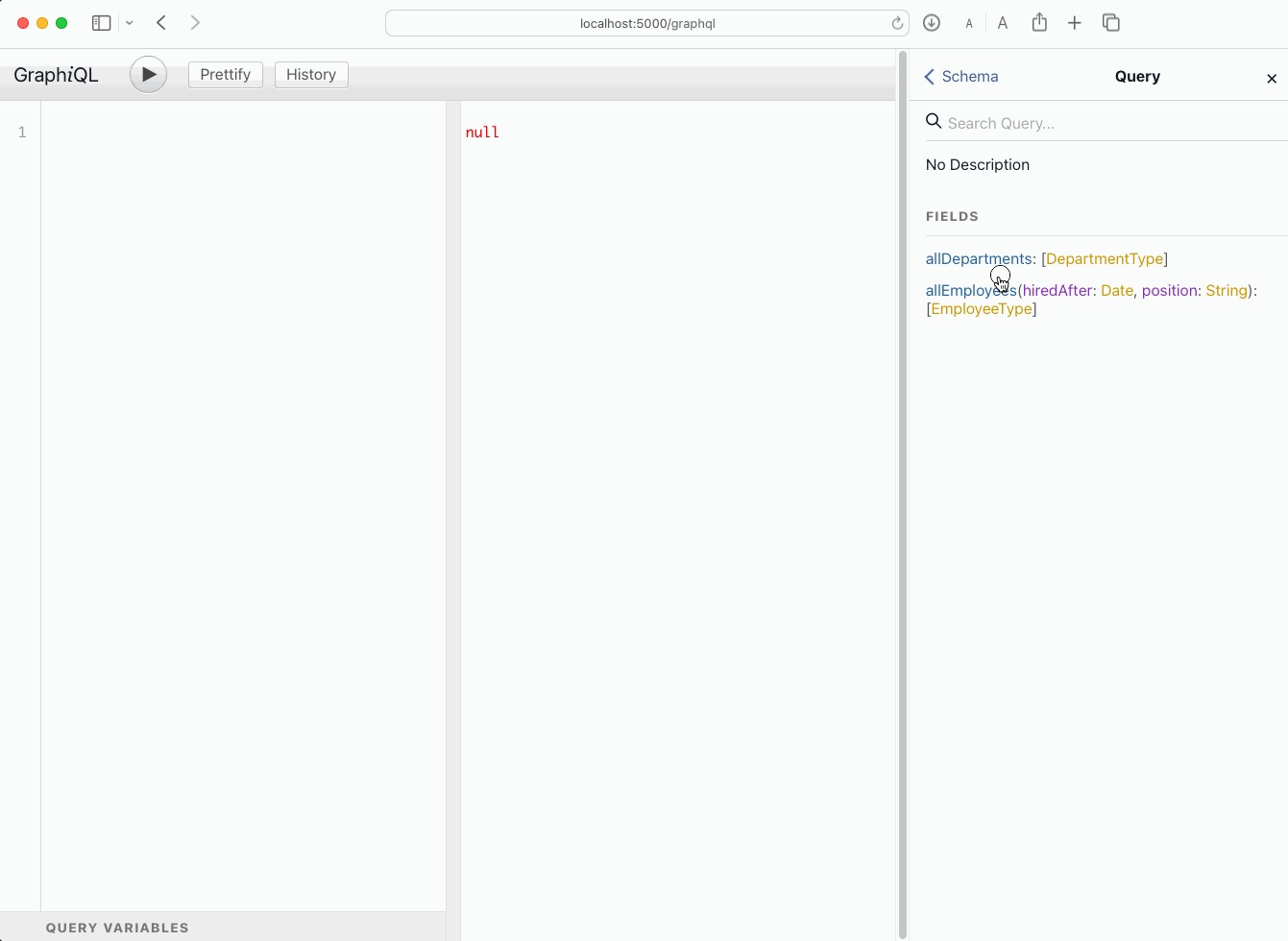
GraphQL Best Practices
If you need to work with very large datasets or you need pagination, consider using Relay. Relay introduces Edge and Node concepts for efficient pagination and handling of large datasets.
In the related OpenExchange application you will also find a GraphQL schema implementation using Relay.
Deploying Your WSGI Application in InterSystems IRIS
In case you don't know what WGSI is, just check this article WSGI Support Introduction and the related posts that explain how to deploy Flask, Django and FastAPI applications in IRIS by @Guillaume Rongier
In a nutshell, InterSystems IRIS can deploy WGSI applications now so you can deploy your GraphQL server.
You only need to set up a web application like this:

After that, your endpoint will be http://localhost:52773/graphqlserver/graphql
Conclusion
Congratulations! You’ve built a GraphQL server on top of InterSystems IRIS, explored its basic features, and even deployed it as a WSGI application. This demonstrates how flexible API approaches can integrate seamlessly with enterprise-grade data platforms like InterSystems IRIS.
If you are still awake, thanks for reading 😄! I'll give you a final fun fact:
- Did you know that GraphQL was developed at Facebook in 2012 and open-sourced in 2015? Now it powers sites like GitHub, Shopify, and Twitter.
.png)
.png)