This article will cover turning over control of provisioning the InterSystems Kubernetes Operator, and starting your journey managing your own "Cloud" of InterSystems Solutions through Git Ops practices. This deployment pattern is also the fulfillment path for the PID^TOO||| FHIR Breathing Identity Resolution Engine.
Git Ops
I encourage you to do your own research or ask your favorite LLM about Git Ops, but I can paraphrase it here for you as we understand it. Git Ops is an alternative deployment paradigm, where the Kubernetes Cluster itself is "pulling" updates from manifests that reside in source control to manage the state of your solutions, making "Git" an integral part of the name.
Prerequisites
- Provision a Kubernetes Cluster , this has been tested on EKS, GKE, and MicroK8s Clusters
- Provision a GitLab, GitHub, or other Git Repo that is accessible by your Kubernetes Cluster
Argo CD
The star of our show here is ArgoCD, which provides a declarative approach to continuous delivery with a ridiculously well done UI. Getting the chart going on your cluster is a snap with just a couple of strokes on your cluster.
kubectl create namespace argocd
kubectl apply -n argocd -f \
https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yaml
Let's go get logged into the UI for ArgoCD on your Kubernetes Cluster, to do this, you need to grab the secret that was created for the UI, and setup a port forward to make it accessible on your system.
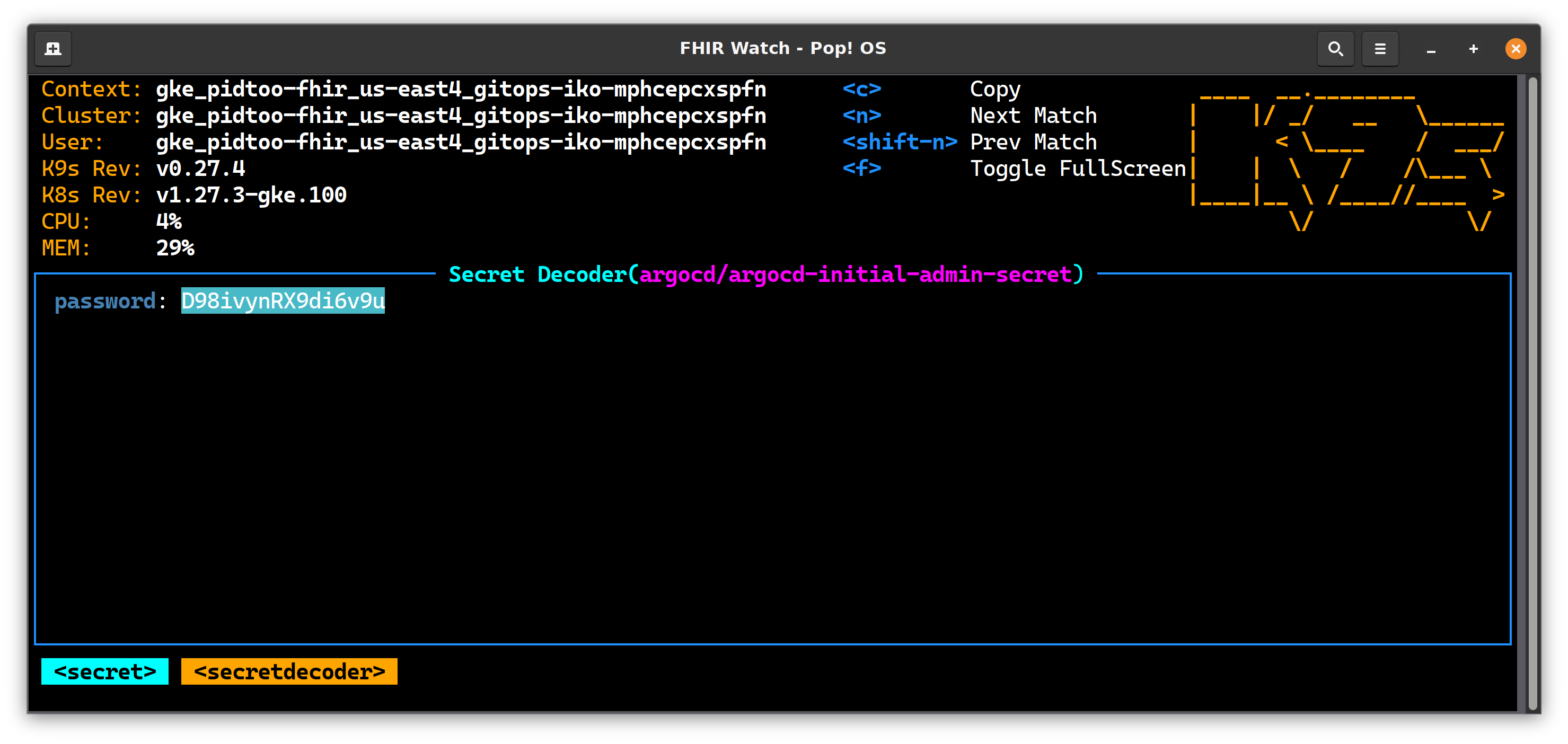
Grab Secret
Decrypt it and put it on your clipboard.
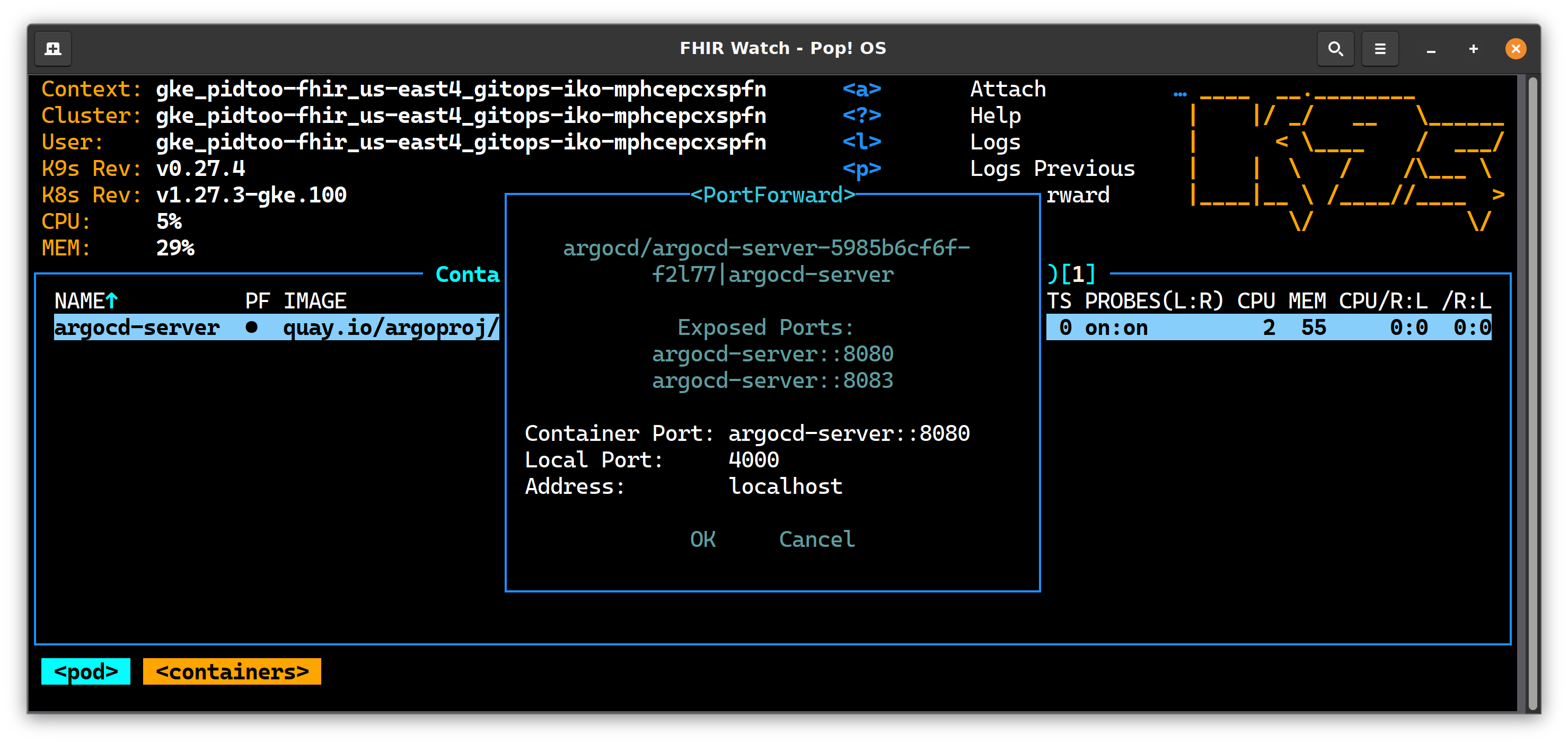
Port Forward
Redirect port 4000 (or whatever) to your local host
UI
Navigate to https://0.0.0.0:4000 and supply the secret to the login screen and login.

InterSystems Kubernetes Operator (IKO)
Instructions for obtaining the IKO Helm chart in the documentation itself, once you get it, check it in to your git repo in a feature branch. I would provide a sample repo for this, but unfortunately cant do it without violating a re-distribution as it does not appear the chart is available in a public repository.
Create yourself a feature branch in your git repository and unpack the IKO Helm chart into a single directory. As below, this is iko/iris_operator_amd-3.5.48.100 off the root of the repo.
On feature/iko branch as an example:
├── iko
│ ├── AIKO.pdf
│ └── iris_operator_amd-3.5.48.100
│ ├── chart
│ │ └── iris-operator
│ │ ├── Chart.yaml
│ │ ├── templates
│ │ │ ├── apiregistration.yaml
│ │ │ ├── appcatalog-user-roles.yaml
│ │ │ ├── cleaner.yaml
│ │ │ ├── cluster-role-binding.yaml
│ │ │ ├── cluster-role.yaml
│ │ │ ├── deployment.yaml
│ │ │ ├── _helpers.tpl
│ │ │ ├── mutating-webhook.yaml
│ │ │ ├── service-account.yaml
│ │ │ ├── service.yaml
│ │ │ ├── user-roles.yaml
│ │ │ └── validating-webhook.yaml
│ │ └── values.yaml
IKO Setup
Create isc namespace, and add secret for containers.intersystems.com into it.
kubectl create ns isc
kubectl create secret docker-registry \
pidtoo-pull-secret --namespace isc \
--docker-server=https://containers.intersystems.com \
--docker-username='ron@pidtoo.com' \
--docker-password='12345'
This should conclude the setup for IKO, and enable it's delegate it entirely through Git Ops to Argo CD.
Connect Git to Argo CD
This is a simple step in the UI for Argo CD to connect the repo, this step ONLY "connects" the repo, further configuration will be in the repo itself.

Declare Branch to Argo CD
Configure Kubernetes to poll branch through Argo CD values.yml in the Argo CD chart. It is up to you really for most of these locations in the git repo, but the opinionated way to declare things in your repo can be in an "App of Apps" paradigm.
Consider creating the folder structure below, and the files that need to be created as a table of contents below:
├── argocd
│ ├── app-of-apps
│ │ ├── charts
│ │ │ └── iris-cluster-collection
│ │ │ ├── Chart.yaml ## Chart
│ │ │ ├── templates
│ │ │ │ ├── iris-operator-application.yaml ## IKO As Application
│ │ │ └── values.yaml ## Application Chart Values
│ │ └── cluster-seeds
│ │ ├── seed.yaml ## Cluster Seed
Chart
apiVersion: v1
description: 'pidtoo IRIS cluster'
name: iris-cluster-collection
version: 1.0.0
appVersion: 3.5.48.100
maintainers:
- name: intersystems
email: support@intersystems.com
IKO As Application
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: iko
namespace: argocd
spec:
destination:
namespace: isc
server: https://kubernetes.default.svc
project: default
source:
path: iko/iris_operator_amd-3.5.48.100/chart/iris-operator
repoURL: {{ .Values.repoURL }}
targetRevision: {{ .Values.targetRevision }}
syncPolicy:
automated: {}
syncOptions:
- CreateNamespace=true
IKO Application Chart Values
targetRevision: main
repoURL: https://github.com/pidtoo/gitops_iko.git
Cluster Seed
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: gitops-iko-seed
namespace: argocd
labels:
isAppOfApps: 'true'
spec:
destination:
namespace: isc
server: https://kubernetes.default.svc
project: default
source:
path: argocd/app-of-apps/charts/iris-cluster-collection
repoURL: https://github.com/pidtoo/gitops_iko.git
targetRevision: main
syncPolicy:
automated: {}
syncOptions:
- CreateNamespace=true
Seed the Cluster!
This is the final on interacting with your Argo CD/IKO Cluster applications, the rest is up to Git!
kubectl apply -n argocd -f argocd/app-of-apps/cluster-seeds/seed.yaml
Merge to Main
Ok, this is where we see how we did in the UI, you should immediately start seeing in Argo CD applications starting coming to life.
The apps view:
InterSystems Kubernetes Operator View

Welcome to GitOps with the InterSystems Kubernetes Operator!
Git Demos are the Best! - Live October 19, 2023
Ron Sweeney, Principal Architect Integration Required, LLC (PID^TOO) Dan McCracken, COO, Devsoperative, INC